SAP S/4HANA and Azure Databricks are two leading platforms in modern data architectures, each playing a pivotal role in how enterprises manage, process, and analyze data. This article is designed for data architects, IT leaders, business analysts, and enterprise decision-makers seeking to understand the comparison and integration of SAP S/4HANA and Azure Databricks within enterprise data architectures.
We will explore the core functions, strengths, and integration points of SAP S/4HANA and Azure Databricks, providing a direct comparison and practical guidance for leveraging both platforms in modern, scalable data environments based on the current NATEK project.
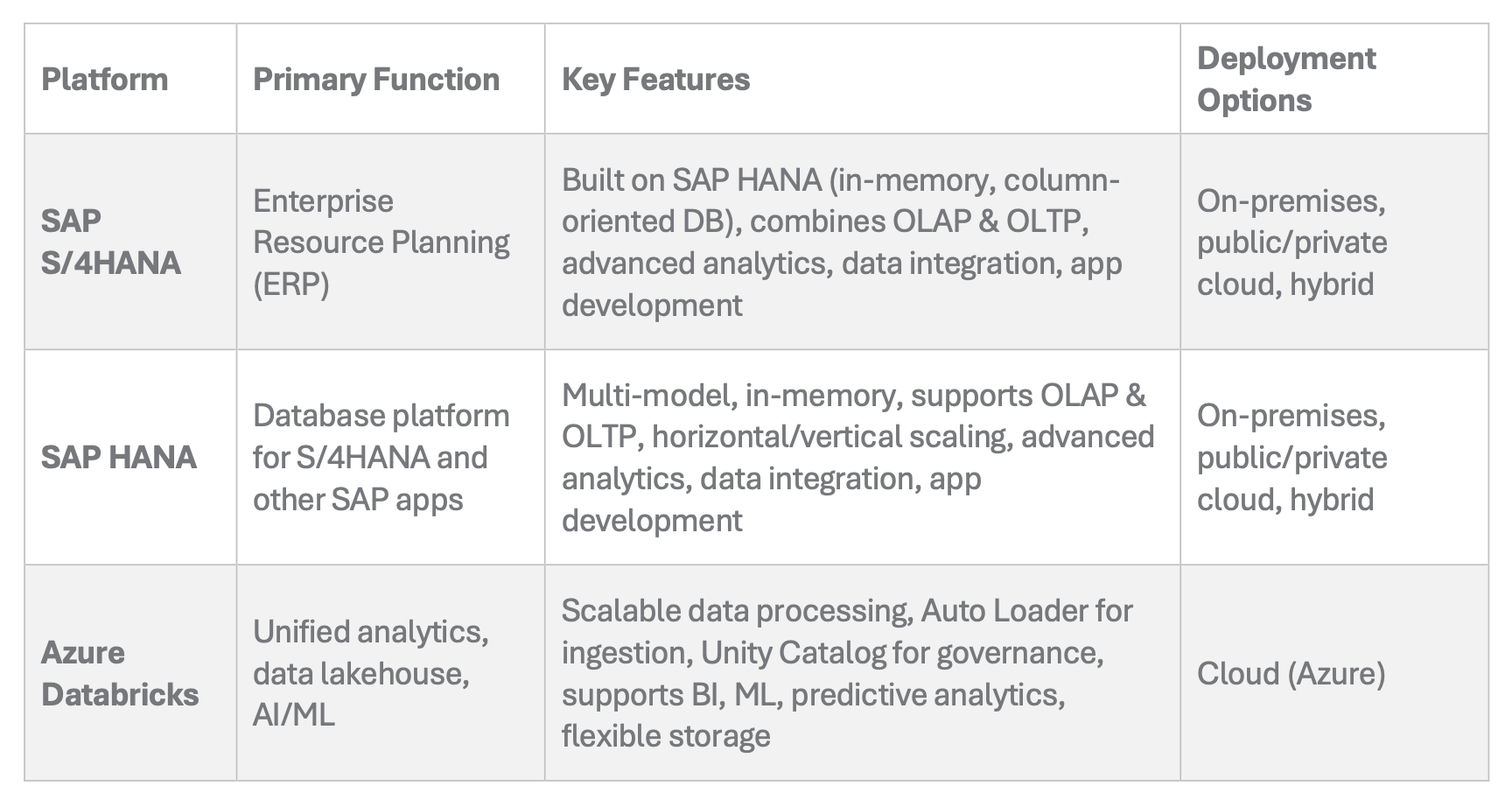
SAP HANA is a column-oriented, in-memory relational database that combines online analytical processing (OLAP) and online transactional processing (OLTP) operations into a single system. It stores data in its memory instead of on disk, enabling high-speed data processing. SAP S/4HANA is an ERP suite built specifically to run on the SAP HANA platform, leveraging its advanced in-memory capabilities for enterprise operations.
Summary Comparison: SAP S/4HANA vs Azure Databricks
In many organizations, ERP systems such as SAP S/4HANA remain the system of record, managing core transactional data: finance, logistics, sales, often built and refined over decades. At the same time, companies are increasingly building data platforms to integrate, process, and analyze data across multiple systems.
In NATEK's project, the architecture reflects this shift:
- Data is extracted from various data sources, including databases, data lakes, and cloud storage across multiple systems (including SAP and non-SAP sources)
- It is ingested into cloud storage (Azure)
- Then processed and modeled in Azure Databricks
“We integrate data from multiple systems, not just one. SAP is often just part of the bigger picture, one of many sources feeding into the platform.”

Modern data platforms enable organizations to explore data from multiple sources for analytics, BI, and data science.
This reflects a broader industry trend: ERP is no longer the only center of gravity for data. Historically, organizations implemented separate systems, such as data warehouses and data lakes, as siloed architectures to prevent resource contention. Integration efforts now focus on overcoming the complexity, higher costs, and data consistency issues caused by these silos.
With this architectural shift, effective data management and governance become critical to ensure data quality, consistency, and security across integrated platforms.
Data Management and Governance
Effective data management and governance are foundational to any successful data-driven organization, especially when integrating platforms like SAP S/4HANA and Azure Databricks. With the vast amounts of data generated and processed daily, organizations ensure that their data is accurate, consistent, and secure. The SAP HANA database plays a critical role in this landscape, offering advanced database management capabilities that support storing and managing large volumes of enterprise data with high performance.
Data governance goes beyond technology. It encompasses the policies, procedures, and controls that regulate how data is accessed, used, and protected. By implementing strong data governance frameworks, organizations can prevent data duplication, maintain high data quality, and enforce consistent security standards across all systems. This is particularly important when data flows between SAP HANA and external analytics engines like Databricks or Snowflake, as it helps avoid inconsistencies and ensures that only authorized users can access sensitive information.
A robust approach to data management and governance not only supports compliance and risk mitigation but also enables organizations to maximize the value of their data assets. By leveraging advanced database management systems and clear governance policies, businesses can confidently scale their data operations and drive innovation without compromising on quality or security.
With governance in place, organizations can more confidently extend their analytics capabilities beyond SAP, leveraging external platforms for advanced insights.
Why Companies Extend Beyond SAP for Analytics
SAP HANA's Analytical Capabilities
SAP has significantly evolved, especially with the introduction of S/4HANA and its in-memory capabilities. SAP HANA is a multi-model database that stores data in memory instead of on disk, enabling high-speed data processing. This architecture allows for much faster access to data and supports embedded analytics through technologies like CDS Views.
However, there are architectural considerations.
ERP systems are fundamentally transactional systems, optimized for:
- high-volume writes
- consistency
- operational performance
SAP HANA serves as a database management system and is unique in its speed compared to other systems on the market today, thanks to its data in-memory approach.
While they can support analytics to a degree, scaling complex analytical workloads directly on transactional systems can be limiting. SAP HANA combines online analytical processing (OLAP) and online transactional processing (OLTP) into a single system, allowing both advanced analytics and high-speed transactions within its column-oriented in-memory database design.
“You can use S/4HANA for analytics up to a certain point, but it’s still a transactional system. You wouldn’t want to overload it with heavy analytical queries.”
This aligns with SAP’s own architectural guidance, where analytical workloads are often separated into dedicated environments such as SAP BW/4HANA or SAP Datasphere (Source: SAP Help Portal, 2025). SAP HANA supports terabytes of data in a single server and can scale further using a shared-nothing architecture across multiple servers in a cluster. It is deployable on-premises, in public or private clouds, and in hybrid scenarios. SAP HANA includes advanced analytical processing, data integration, and application development capabilities.
This leads us to consider how external platforms like Azure Databricks or Snowflake complement SAP systems in modern data architectures.
Where Databricks Brings Value as a Data Lakehouse
Databricks Integration Workflow
Platforms like Azure Databricks are designed specifically for:
- large-scale data processing
- integration across multiple systems
- advanced analytics and machine learning
Databricks is built to handle big data workloads that are highly scalable, efficiently managing diverse data types, including structured, semi-structured, and unstructured data across enterprise environments.
One of their biggest strengths is flexible integration. Databricks supports structured data, robust metadata management, and unified governance, enabling centralized access control and consistent security policies across multiple data sources.
In NATEK's project:
- data is extracted using specialized tools
- loaded into cloud storage
- processed in Databricks using optimized pipelines
Data lakehouse architecture, as enabled by Databricks, blends the key benefits of data lakes and data warehouses. This unified approach allows organizations to capture all types of data, reduce ETL data transfers, consolidate resources, and provide a single source of truth for analytics and decision-making. The low-cost cloud object storage of data lakehouses allows you to decouple compute from storage, simplifying architecture by removing silos and enabling flexible, scalable, and agile data management. Data lakehouses also support advanced machine learning and serve as a comprehensive AI platform, empowering teams to leverage business intelligence, predictive analytics, and real-time insights.
This is particularly valuable when:
- data comes from multiple heterogeneous systems
- datasets are large (hundreds of millions of records)
- advanced transformations or AI use cases are required
- you need to prepare data for analytics or machine learning
- data professionals want to write code in SQL, Python, Scala, or R for custom workflows
- streaming data and new data must be integrated for real-time analytics
“When you need to integrate data from many different environments, cloud platforms like Databricks are a natural fit.”
The emergence of the data lakehouse architecture further transforms how organizations approach analytics and data storage, especially when integrating SAP applications with Azure Databricks.
Data Lakehouse Architecture
The emergence of the data lakehouse architecture has transformed how organizations approach analytics and data storage. By combining the best features of data warehouses and data lakes, a data lakehouse provides a single platform for storing, processing, and analyzing both structured and unstructured data at scale. This unified approach is particularly powerful when integrating SAP applications with Azure Databricks.
With a data lakehouse, organizations can ingest data from SAP and other enterprise sources, store it efficiently, and make it readily available for advanced analytics, machine learning, and AI applications. This architecture delivers speed and flexibility, allowing teams to analyze large datasets in real time and generate valuable insights that drive business outcomes.
The single platform nature of the data lakehouse eliminates data silos and simplifies data management, making it easier to support a wide range of analytics, from operational reporting to predictive modeling. By leveraging the open lakehouse architecture of Databricks alongside SAP’s robust data foundation, organizations can unlock new opportunities for innovation and deliver analytics that meet evolving business needs.
However, integrating data from SAP and other enterprise systems into a unified platform presents its own set of challenges.
The Data Governance and Integration Challenge
Challenges in Data Extraction
Moving data out of ERP systems is not always straightforward. SAP ecosystems are highly structured, and data extraction often requires:
- dedicated tools
- APIs
- or integration layers
During data extraction and management, log files play a crucial role in ensuring data durability and transaction management, supporting reliable integration processes. Disk space considerations are also important, as SAP HANA's in-memory architecture optimizes storage and scalability for integration scenarios.
In this case, a specialized integration tool, called Lobster, was used to extract SAP data into Azure before processing it further. Data lakehouses, in particular, support data science workflows by providing accessible, organized data for analysis.
This reflects a broader reality: integration is often the most complex part of the architecture.
SAP has been addressing this with solutions like SAP Datasphere and SAP Business Data Cloud, and through partnerships with cloud providers (including Microsoft). These developments aim to simplify data access and reduce friction in hybrid architectures.
(Source: SAP & Microsoft partnership announcements, 2024–2025)
Given these integration challenges, it’s important to recognize that external data platforms are not replacements for ERP systems, but rather serve specialized roles within the enterprise architecture.
Not a Replacement, but a Division of Responsibilities
Despite the growing role of external data platforms, the idea of replacing ERP systems entirely is unrealistic especially in large enterprises.
“ERP systems are built over decades. Replacing them entirely would take years, if not decades. They remain the core.”
This leads to a more pragmatic architecture:

The next frontier in this division of responsibilities is the integration of AI capabilities across both platforms.
The Role of AI
One of the most interesting developments is the intersection of data platforms and AI. During internal experiments, the team explored Databricks capabilities combined with AI, including:
- automatic table relationship discovery
- natural language querying
- automated SQL generation
SAP HANA also supports application development, providing a robust environment for building, deploying, and managing AI-powered application.
In practical terms, this means users can:
- ask questions in plain language
- generate queries automatically
- retrieve insights without deep technical knowledge
The direction is clear: data platforms are becoming intelligent interfaces, not just processing engines. As AI capabilities expand, organizations must also consider the cost implications of scaling analytics and machine learning workloads in the cloud.
Costs and Trade-offs
Cloud data platforms bring flexibility but also new cost models. Unlike on-premise systems, every operation in platforms like Azure Databricks:
- consumes compute resources
- translates directly into cost
Processing massive amounts of data in the cloud can significantly increase costs if not managed efficiently, making it crucial to optimize both storage and compute usage.
This introduces a new discipline: cost-aware data engineering.
As Tomasz noted:
- large-scale processing is powerful, but not free
- inefficient queries can quickly increase costs
This is an important consideration often overlooked in early-stage discussions. Despite these trade-offs, many organizations are already realizing significant value by integrating SAP S/4HANA and Azure Databricks in real-world scenarios.
What Will the Future Look Like?
Looking ahead, one thing seems certain:
- ERP systems like SAP S/4HANA will remain the core transactional backbone
- Data platforms like Azure Databricks will continue to grow as the center of analytics and AI
The open question is not whether these worlds will coexist but how tightly they will integrate. As the Tomasz summarizes:
“The core will likely remain in ERP, but the analytical layer will continue to evolve with platforms like Databricks.”
Tomasz Poszwa, Data Engineer at NATEK
To fully realize the benefits of this evolution, it will be crucial to integrate new data quickly, minimizing latency so that real-time analytics and business agility are supported.
This brings us to the final consideration: how to design architectures that maximize the strengths of both SAP S/4HANA and Azure Databricks.
Conclusion
Comparing SAP S/4HANA and Azure Databricks as direct alternatives misses the point.
They serve different purposes:
- one runs the business
- the other extracts value from its data
The most effective architectures today and likely in the future is to combine both: leveraging ERP for stability and transactional integrity and using data platforms for scalability, integration, and innovation. In that sense, the real question is no longer SAP vs Databricks. It is how do we design an architecture where both can deliver their full potential?
We wrote this article in cooperation with Tomasz Poszwa, a Data Engineer, who provides comprehensive care in the field of Azure Databricks to improve existing processes for NATEK clients. Need some assistance in your SAP projects? Go to our contact page or message our Sales Prospection Team Lead Andrzej Osman on LinkedIn or at andrzej.osman@natek.eu to tell us about your needs. Contact us and #growITwithus!